Getting started
28 Jun 2015Howdy! Welcome to my blog. A bit of background about who I am and where I am right now: I’m finishing up a PhD in plant molecular genetics at the University of Cambridge (and by finishing up I mean I’m waiting for my supervisor to send me her final edits before I can submit for real!). I’m currently in the other Cambridge (MA, just outside of Boston) where I’m spending the summer visiting friends and learning data science. I have a place on the Science to Data Science(otherwise known as ‘S2DS’) 2015 programme in London in August, which is essentially a summer school to help people with analytic PhDs transition into the data science industry. A big component of S2DS is about working with industry sponsors on real-world projects. It’s going to be a really good opportunity to get some hands-on experience in data analytics.
I’m a couple of weeks into this trip, so I thought I’d use this first post to outline what I’ve been doing so far, what tools I’m using, and what I want to achieve in the next few weeks:
Data science curriculum
There are so many open source/freely-available data science/programming/stats etc. learning tools on the internet right now, it has actually been difficult to pare them down and pick out what courses would be the best use of my time. It doesn’t help that the data science landscape looks like this. The blogs and websites of others who have done similar things in this space have been useful guides through the fog. Even so, I am overwhelmed with choice. I’ve put together my own spreadsheet of training resources that I’m interested in doing.
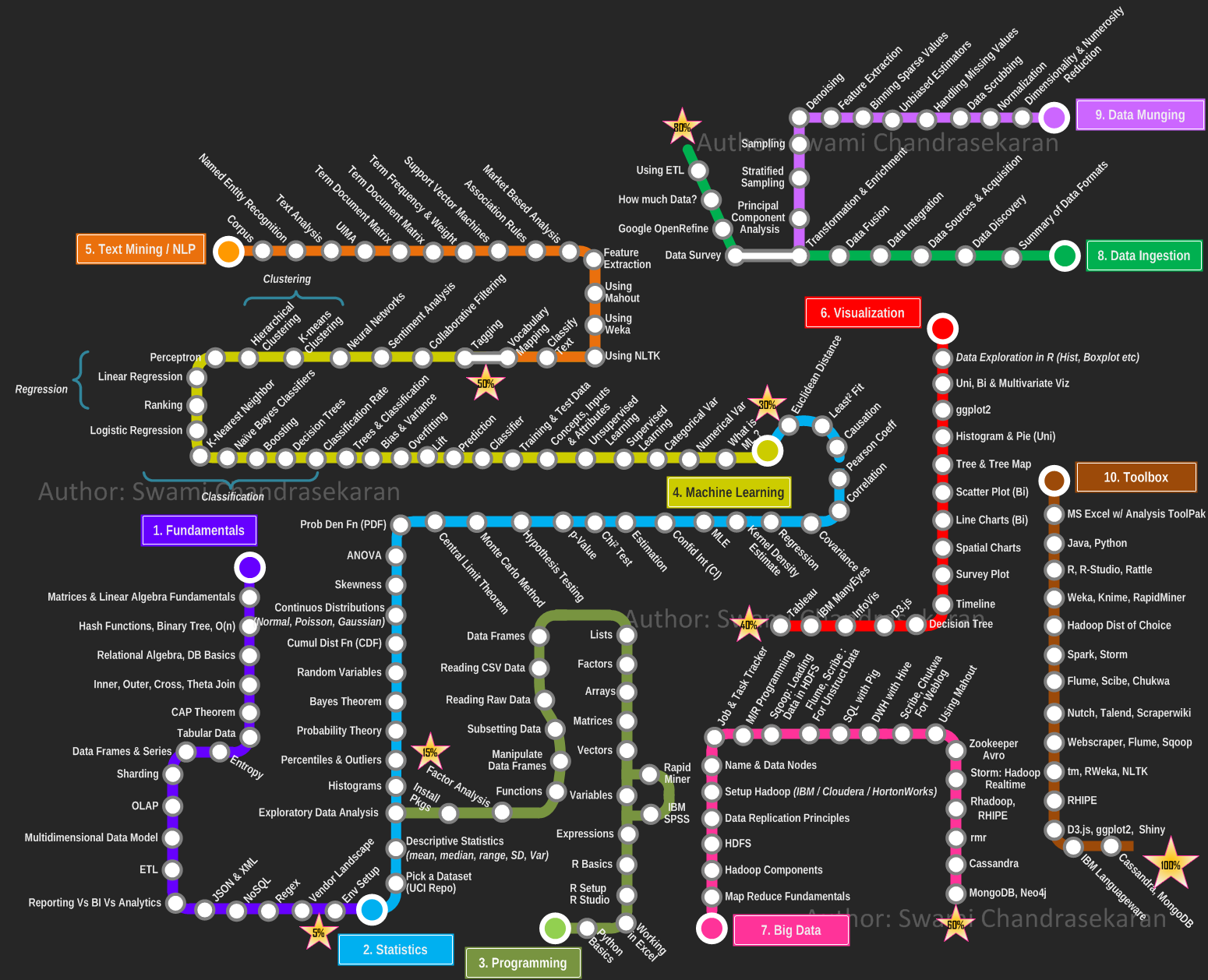{kind=link}
This summer, I’d be happy if I managed to get four courses completed before S2DS (which might be super optimistic):
-
Harvard’s CS109 Data Science course
I found this course because it was recommended on here. This isn’t technically a MOOC, it’s just Harvard being nice and making their undergraduate course content available online. So, even though all of the lecture videos are available and the homeworks are available on Github, I’m still finding it difficult to follow some of the content.However, an advantage is that it’s only a year old and I like that it’s really up to date with the Python tools it’s using (the homeworks so far have all been answering questions using Pandas in an iPython notebook). We’ll see how far I can get before things stop being useful.
-
Stanford’s Introduction to Machine Learning (via Coursera)
I’m told machine learning may be useful for the S2DS project I’ll be working on this summer. This course came highly recommended by Insight as a very good introduction to machine learning (in fact, it’s cited on the course website as being the MOOC that launched Coursera in the first place). My only previous experience with machine learning has been via a one-day intensive course, so this seemed like a good place to start. I’m already finding it much easier to follow a structured course than just reading through course materials. My only gripe is that all the exercises are done in MatLab, when I’d rather do them in Python, although Andrew Ng says at the start ‘trust me, you’ll learn faster this way’. I’ll trust you, Andrew.
-
Harvard’s 110 Introduction to Probability (and consequent courses)
Once again, I found this recommended here. I have previously taken stats courses during high school and during my undergraduate degree, and I have used statistics to compare biological data in my PhD and during my work experience year in Kew Gardens, London. However, I’d like to get a stronger and broader knowledge of statistics outside of tests commonly used in the life sciences. I’m yet to start this course.
-
Relational databases e.g. SQL
The project this summer will involve working with relational databases, something I have zero experience in. I’m planning on doing some exercises on SQLZoo as preparation.
Tools for work hacking
I like to be organised with my work habits, so finding systems that maximise my efficiency and sustain my motivation are important to me (consequently, this seems to be a large part of what one learns during a PhD, especially during writing-up stages). I’m a fan of Cal Newport’s blog, where he writes extensively about finding space for deep work (i.e. meaningful, cognitively demanding work, which in my case means stretching myself to actually grok these new concepts/tools ). I’d like to try systematically applying some of these principles to my own work habits. It’ll probaby take time and trial and error to work out the best system for me.
For the time being, I’m breaking up my working hours using the pomodoro techinique, a habit carried over from hours of thesis-writing. I’m also using toggl to track my work activities. Toggl has a really nice interface, but a big drawback from my perspective is that if you want to export to your data as a csv file then you have to pay monies for the premium version. I’d like access to my own data so I can use it for data exploration when I’ve racked up enough hours. So, toggl is just a standby until I get around to customising a Python tool I made previously with a friend that logs Google calendar events from the command line. It should only be a few additions to make it so that each activity also gets added to a csv file. Maybe I’ll write a blog post about it!
Blogging
Blogging is a nice way to get keep a track of what I’ve been working on, and tell others about it. I’ve done an introduction to web development course with CodeFirst Girls. However, I’m making this blog in Jekyll and hosting it on Github, which means I can write it all in markdown and never have to touch any HTML or CSS :p. Jekyll was built for static blogs and has a lot of nice functionality for this, which you an read about here and here. I am using the hyde theme. Comments are implemented using Disqus, which was surprisingly easy in Jekyll.